


Evaluating the Quality of Predictive Models
Predictive models are the backbone of modern data analysis, particularly in the context of machine learning and artificial intelligence. To assess the quality of a predictive model, various metrics are used to accurately evaluate its effectiveness. In this post, we will discuss key metrics such as accuracy, sensitivity, specificity, precision (PPV), negative predictive value (NPV), F1-score, and others. Each of these metrics has its specific applications and limitations, which should be considered when interpreting the results.
1. Accuracy
- Definition: Accuracy measures the proportion of correct predictions out of the total number of cases. It is an intuitive and widely used metric.
- Formula:
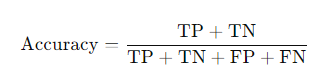
- Explanation of terms:
- TP (True Positive): The number of correctly classified positive cases.
- TN (True Negative): The number of correctly classified negative cases.
- FP (False Positive): The number of cases incorrectly classified as positive.
- FN (False Negative): The number of cases incorrectly classified as negative.
- When to Use: Accuracy is useful when the dataset is balanced, meaning the number of positive and negative cases is comparable. However, in imbalanced datasets, accuracy can be misleading, as it might not reflect the model’s true performance. For example, a model that always classifies all cases as negative will achieve high accuracy with a large number of negative cases, even though it does not actually identify any positives.
- Example: If we have a predictive model that classifies whether an e-mail is spam, and the model correctly classifies 90 out of 100 e-mails (of which 80 are true negatives and 10 are true positives), the accuracy is 90%.
2. Sensitivity (Recall)
- Definition: Sensitivity, or true positive rate, measures the percentage of actual positives that are correctly identified by the model.
- Formula:
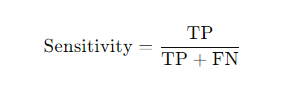
- Explanation of terms:
- TP (True Positive): The number of correctly classified positive cases.
- FN (False Negative): The number of cases incorrectly classified as negative.
- When to Use: Sensitivity is crucial in situations where it’s important to identify all positive cases, such as in medical diagnostics. Low sensitivity could result in missed positive cases, which can be dangerous.
- Example: Suppose that in medical testing, the model is tasked with detecting a disease. If in a group of 100 people 20 are sick (positive cases), and the model correctly identified 18 of them, then the sensitivity is 90%.
3. Specificity
- Definition: Specificity measures the percentage of actual negatives that are correctly identified by the model.
- Formula:
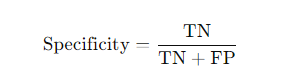
- Explanation of terms:
- TN (True Negative): The number of correctly classified negative cases.
- FP (False Positive): The number of cases incorrectly classified as positive.
- When to Use: Specificity is important when it is crucial to avoid false positives, such as in screening tests where unnecessary further testing or treatment could have negative consequences. An example is screening tests, where too many false positives can lead to unnecessary further testing or interventions.
- Example: If out of a group of 80 healthy individuals, the model correctly classified 70 as healthy, the specificity is 87.5%.
4. Precision (PPV)
- Definition: Precision measures the proportion of true positives among all positive predictions.
- Formula:

- Explanation of terms:
- TP (True Positive): The number of correctly classified positive cases.
- FP (False Positive): The number of cases incorrectly classified as positive.
- When to Use: Precision is key in scenarios where the cost of false positives is high, such as in recommendation systems where inaccurate suggestions can lead to user dissatisfaction.
- Example: If a model classifying emails as spam identified 15 emails as spam, of which 12 were actually spam, the precision is 80%.
5. F1-Score
- Definition: The F1-score is the harmonic mean of precision and sensitivity, providing a balance between the two.
- Formula:
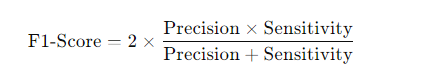
- Explanation of terms:
- Precision: The proportion of true positives among all positive predictions.
- Sensitivity: The percentage of actual positives that are correctly identified.
- When to Use: The F1-score is particularly useful when you need to balance precision and sensitivity, making it a strong metric in situations where both false positives and false negatives are costly.
- Example: If the model’s precision is 75% and sensitivity is 60%, the F1-score will be about 66.7%.
6. Negative Predictive Value (NPV)
- Definition: NPV measures the proportion of true negatives among all negative predictions.
- Formula:
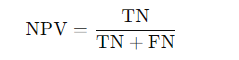
- Explanation of terms:
- TN (True Negative): The number of correctly classified negative cases.
- FN (False Negative): The number of cases incorrectly classified as negative.
- When to Use: NPV is important in medical contexts where confirming that a negative result is truly negative is crucial to avoid missing a diagnosis.
- Example: If out of a group of 70 people identified as healthy by the model, 65 are actually healthy, then the NPV is about 92.9%.
7. ROC and AUC
- Definition: ROC (Receiver Operating Characteristic) is a graph showing the trade-off between sensitivity and specificity. AUC (Area Under the Curve) provides a single value that summarizes the model’s ability to distinguish between positive and negative cases.
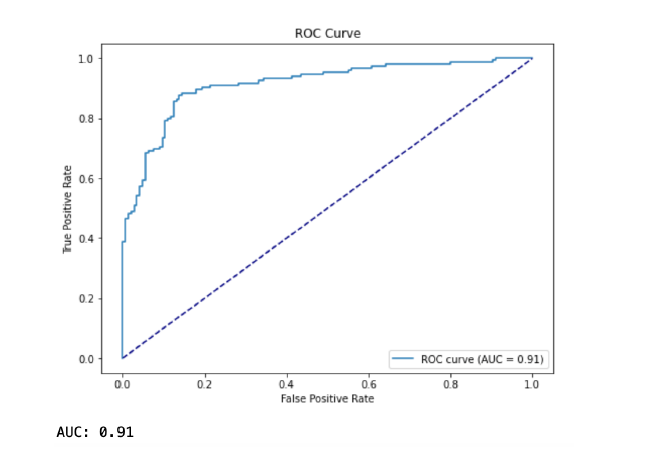
- Explanation of terms:
- ROC Curve: A plot showing the relationship between sensitivity and 1-specificity at various threshold settings.
- AUC (Area Under the Curve): The area under the ROC curve, representing the model’s ability to distinguish between positive and negative cases.
- When to Use: AUC is a powerful metric for evaluating the overall performance of a model, especially when dealing with imbalanced data.
- Example: A model with AUC = 0.5 works the same as random guessing, while a model with AUC = 1 perfectly classifies all cases.
Conclusion
Each of these metrics has its own role in evaluating predictive models, and no single metric can provide a complete picture. It’s crucial to choose the right combination of metrics based on the specific problem you are addressing and to interpret the results in the context of the model’s intended use. By analyzing metrics such as precision, recall, F1-score, and AUC, you can gain a deeper understanding of your model’s performance and make more informed decisions.
If you’re interested in learning more about predictive models or need guidance on applying these metrics to your specific projects, feel free to reach out to us through our contact form. We’d be happy to answer your questions and assist you in making the most of your AI initiatives.